
GlainKDB
How we’re different from traditional data warehouses
A New Approach to Data Warehousing
GlainDB is pioneering a fundamentally different approach to data warehousing by combining two powerful innovations: the performance of DuckDB with decentralized infrastructure. This combination delivers high performance, low costs, and true data ownership.

Built on DuckDB: The Future of Data Processing
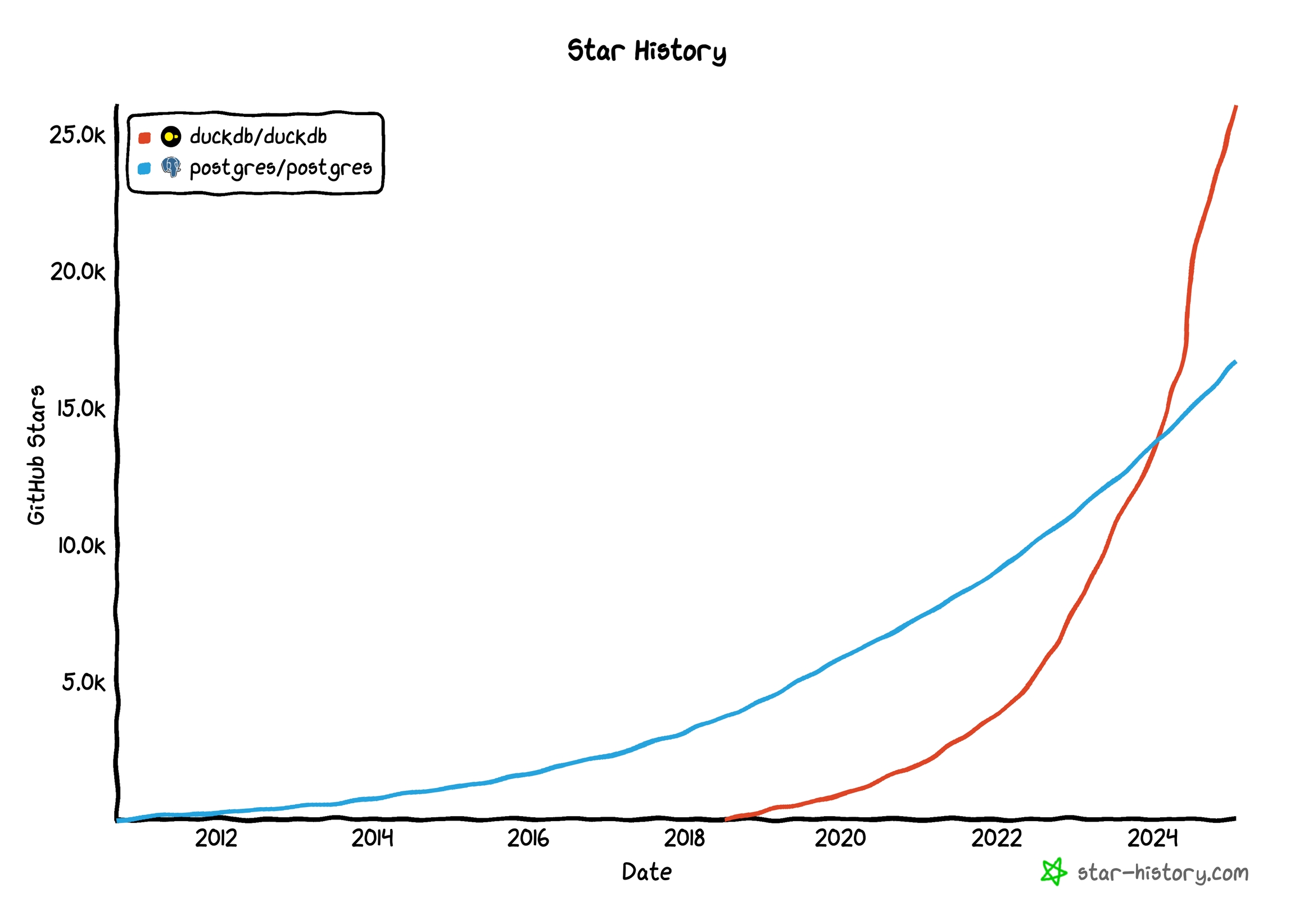
DuckDB represents a fundamental shift in how we process data. While traditional data warehouses rely on distributed systems, DuckDB takes a different approach by focusing on highly efficient single-machine processing. The project has seen explosive growth, surpassing established databases like Postgres in GitHub popularity.
Why DuckDB Is Revolutionary
In-Memory Processing
DuckDB performs computations directly where your data lives, eliminating the “cold-start” problem that plagues distributed systems like Spark. This means no data movement costs and significantly lower latency for most operations.
Vectorized Processing Excellence
Written in C++, DuckDB’s vectorized processing engine can handle datasets much larger than available memory. Recent benchmarks have shown it outperforming Databricks on many operations by avoiding the overhead of data distribution.
Modern Features for Modern Data
DuckDB has rapidly evolved to meet contemporary data needs:
Native support for semi-structured data (JSON, Parquet)
Direct integration with HuggingFace for AI datasets
Built-in support for vector similarity search
Efficient handling of large-scale analytics
SQL-Native Design
Unlike many modern data solutions that require learning new query languages or APIs, DuckDB uses standard SQL. This means:
No retraining needed for analysts
Familiar tooling and workflows
Easy integration with existing systems
Complex transformations without new languages
The Hybrid Execution Model
Unlike traditional data warehouses, Glain employs a unique hybrid execution approach:
Local-First: Queries are first evaluated for local execution on your machine
Smart Routing: Large operations or data-intensive queries are automatically routed to the network
Cost Optimization: The system chooses the most efficient execution path based on:
Data size
Query complexity
Physical data location
Available local resources
Decentralized Infrastructure
We’ve built a network of decentralized compute providers that offers several advantages:
Cost Savings: Up to 70% reduction in infrastructure costs compared to traditional warehouses
No Vendor Lock-in: Pay per query with either crypto or traditional payment methods
Flexible Scaling: Access compute resources as needed without long-term commitments
Geographic Optimization: Process data closer to where it’s stored
True Data Ownership
With GlainDB, you maintain complete control of your data:
Choose Your Storage: Use any storage solution including IPFS, Arweave, or traditional options
Flexible Access: Control how your data is accessed and by whom
Direct Monetization: Set your own terms for data sharing and marketplace participation
No Double Storage: Store your data once and access it anywhere
Fair Economics
We’re building a more equitable data ecosystem:
Transparent Pricing: Pay only for what you use
No Credit Systems: No expiring credits or complex pricing tiers
Revenue Sharing: Data providers earn royalties when their data is used
Open Marketplace: Direct connection between data providers and consumers
Last updated